Javier, your number and type of spindles aren't the source of your I/O bottleneck. Your array controller is. Or, more specifically, its lack of enough fast network ports is the problem. The P4300 BK718A model of which you speak only has two 1GbE iSCSI ports. That's only 200 MB/s full duplex. That's less link bandwidth than a single 2 Gbit fiber channel interface. 2 Gbit FC is 2 generations and over 8 years old now. It was superseded by 4 Gbit FC and then 8 Gbit FC, which is the current standard. 8 Gbit FC provides 800 MB/s full duplex bandwidth per link.
Hmm... I do not fully agree with your reasoning. An imap server is a lot of random I/O, not too much bandwith. Our LeftHand Networks have two 1 Gbein adaptive load balancing (a kind of active-active connection), meaning 4 gbps full duplex.
I attach you a screenshot of the perfomance of the lefthand: Average: 15 MB/seg, 1.700 IOPS. Highest load (today) is ~62 MB/seg, with a whooping 9000 IOPS, mucho above the theorical iops of 2 raid5 of 8 disks each (SAS 15K), the cache is working as expected, and queue depth of 226 (a bit overloaded, though)
There are many other fine SAN arrays on the market. I mention Nexsan merely because they are very affordable, fast as hell for the price, easy to manage, and I've used them. Due to the low price, they lack the more advanced features of higher priced units, such as snapshots, remote replication, etc. As I mentioned, I'm not a big fan of relying on SAN controllers to perform all my disaster recovery functions, so I do that with software, such as VCB, and a dedicated backup server with a SAN attached robotic library. Thus, the lack of this functionality in the Nexsan units is not an issue here.
We have more than 65k users, and we need active-active disaster recovery. Half of our ESX cluster & lerfthands are in a location, the other half is in other location, and we have tested that shutting down a complete site we can recover in minutes (simply, the VMs start launching in the other one). Only lefthand (in the cheap market) gave us realtime replication of storage, a kind of "network raid 1" for our storage...
I still think that my problem is IOPs related, no bandwith related. My maximum bandwith today was 60 MB/seg, that fits entirely in 1 Gbps, but the queue depth is high because of the lot of iops (9000) that "only" 16 disks can not handle. I can buy better storage heads to delay all that writes, or avoid a lot of them putting the indexes in a SSD or in a ramdisk.
Thank for all the info, I did not know about Nexsan.
Regards
Javier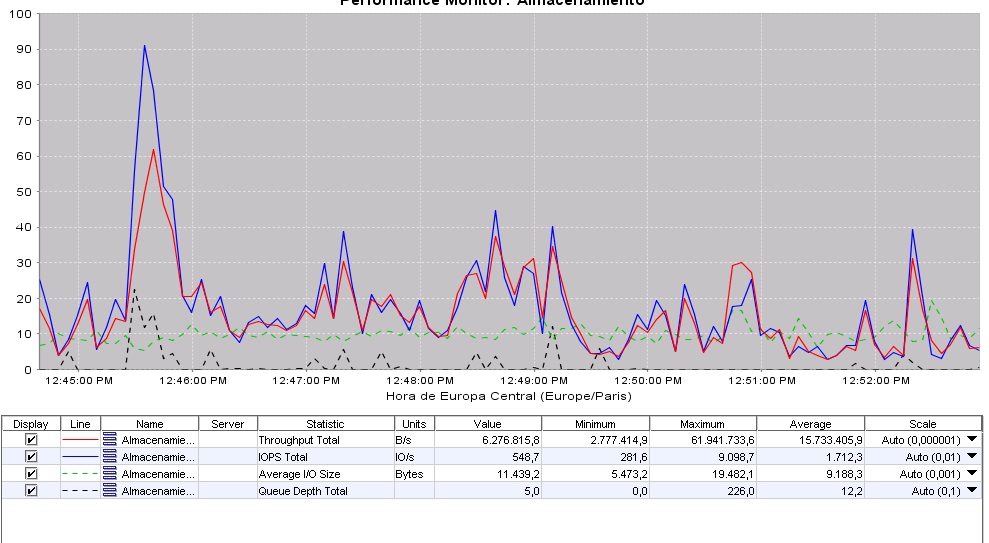{kind=link}