Re: [Dovecot] Question about "slow" storage but fast cpus, plenty of ram and dovecot
Patrick Westenberg put forth on 12/11/2010 5:12 AM:
Stan Hoeppner schrieb:
So, either:
- Move indexes to memory
What steps have to be done and what will the configuration look like to have your indexes in memory?
Regarding Dovecot 1.2.x, for maildir, I believe it would be something like this:
mail_location = maildir:~/Maildir:INDEX=MEMORY
The ":INDEX=MEMORY" disables writing the index files to disk, and as the name implies, I believe, simply keeps indexes in memory.
The docs say:
"If you really want to, you can also disable the index files completely by appending :INDEX=MEMORY."
My read of that is that indexing isn't disabled completely, merely storing the indexes to disk is disables. The indexes are still built and maintained in memory.
Timo, is that correct?
Also, due to the potential size of the index files (mine alone are 276 MB on an 877 MB mbox), you'll need to do some additional research to see if this is a possibility for you. If using a ramdisk, 100 mail boxen like mine would require ~ 27.6 GB or RAM just for the index files. This would not be logical to do or feasible given the amount of RAM required. I don't know if, or how much, storing them in RAM via :INDEX=MEMORY consumes, as compared to using a ramdisk. The memory consumption may be less or it may be more. Timo should be able to answer this, and give a recommendation as to whether this is even a sane thing to do.
-- Stan
On 12.12.2010, at 9.39, Stan Hoeppner wrote:
mail_location = maildir:~/Maildir:INDEX=MEMORY
The ":INDEX=MEMORY" disables writing the index files to disk, and as the name implies, I believe, simply keeps indexes in memory.
I think maybe I shoudn't have called it INDEX=MEMORY, but rather more like INDEX=DISABLE.
"If you really want to, you can also disable the index files completely by appending :INDEX=MEMORY."
My read of that is that indexing isn't disabled completely, merely storing the indexes to disk is disables. The indexes are still built and maintained in memory.
Timo, is that correct?
It's a per-connection in-memory index. Also there is no kind of caching of anything (dovecot.index.cache file, which is where most of Dovecot performance usually comes from).
I don't know if, or how much, storing them in RAM via :INDEX=MEMORY consumes, as compared to using a ramdisk. The memory consumption may be less or it may be more. Timo should be able to answer this, and give a recommendation as to whether this is even a sane thing to do.
I think INDEX=MEMORY performance is going to suck. http://imapwiki.org/Benchmarking explains IMAP performance a bit more. By default Dovecot is the "Dynamically caching server", but with INDEX=MEMORY it becomes "Non-caching server".
Thank you very much for all the responses in this thread. Now I have more questions:
- I have "slow" I/O (about 3.5000-4.000 IOPS, measured via imapsync), if I enable zlib compression in my maildirs, that should lower the number the IOPS (less to read, less to write, less IOPS, more CPU). Dovecot 2.0 is better for zlib (lda support) than dovecot 1.2.X..
- I understand that indexes should go to the fastest storage I own. Somebody talked about storing them in a ramdisk and then backup them to disk on shutdown. I have several questions about that:
- In my setup I have 25.000+ users, almost 7.000.000 messages in my maildir. How much memory should I need in a ramdisk to hold that?
- What happens if something fails? I think that if I lose the indexes (ej: kernel crash) the next time I boot the system the ramdisk will be empty, so the indexes should be recreated. Am I right?
- If I buy a SSD system and export that little and fast storage via iSCSI, does zlib compression applies to indexes?
- Any additional filesystem info? I am using ext3 on RHEL 5.5, in RHEL 5.6 ext4 will be supported. Any performance hint/tuning (I already use noatime, 4k blocksize)?
Regards
Javiermail_location = maildir:~/Maildir:INDEX=MEMORY
The ":INDEX=MEMORY" disables writing the index files to disk, and as the name implies, I believe, simply keeps indexes in memory. I think maybe I shoudn't have called it INDEX=MEMORY, but rather more like INDEX=DISABLE.
"If you really want to, you can also disable the index files completely by appending :INDEX=MEMORY."
My read of that is that indexing isn't disabled completely, merely storing the indexes to disk is disables. The indexes are still built and maintained in memory.
Timo, is that correct? It's a per-connection in-memory index. Also there is no kind of caching of anything (dovecot.index.cache file, which is where most of Dovecot performance usually comes from).
I don't know if, or how much, storing them in RAM via :INDEX=MEMORY consumes, as compared to using a ramdisk. The memory consumption may be less or it may be more. Timo should be able to answer this, and give a recommendation as to whether this is even a sane thing to do. I think INDEX=MEMORY performance is going to suck. http://imapwiki.org/Benchmarking explains IMAP performance a bit more. By default Dovecot is the "Dynamically caching server", but with INDEX=MEMORY it becomes "Non-caching server".
Quoting Javier de Miguel Rodríguez <javierdemiguel@us.es>:
- I understand that indexes should go to the fastest storage Iown. Somebody talked about storing them in a ramdisk and then backup
them to disk on shutdown. I have several questions about that:- In my setup I have 25.000+ users, almost 7.000.000messages in my maildir. How much memory should I
need in a ramdisk to hold that?
Are you using dovecot with them now? If so, then you can figure out who much they are currently using. Otherwise, well, who knows? It will depend on the clients used (for dovecot.index.cache), as well as how often they are accessed (for transaction log), and so on.
Maybe Timo or someone more into the inner workings can give more details.
- What happens if something fails? I think that ifI lose the indexes (ej: kernel crash) the next time I
boot the system the ramdisk will be empty, so the indexes should be
recreated. Am I right?
Yes. If the ramdisk is full, it will switch to INDEX=MEMORY automatically for all new sessions until space frees up. And if you crash without saving the indexes, it will rebuild them when the users reconnect.
- If I buy a SSD system and export that little andfast storage via iSCSI, does zlib compression
applies to indexes?
I don't think so, but maybe Timo can say for sure.
- Any additional filesystem info? I am using ext3 on RHEL 5.5,in RHEL 5.6 ext4 will be supported. Any performance hint/tuning (I
already use noatime, 4k blocksize)?
Only the ext3 commit interval (raising it might lower your I/O on the SAN) I mentioned earlier... But of course, it raises your chances of losing data in a crash (i.e. you could lose more data, since it flushes less often). But it is a good trade off sometimes (I always raise it on my laptops in order to cut down on battery usage).
-- Eric Rostetter The Department of Physics The University of Texas at Austin
Go Longhorns!
Javier de Miguel Rodríguez put forth on 12/12/2010 1:26 PM:
Thank you very much for all the responses in this thread. Now I have more questions:
- I have "slow" I/O (about 3.5000-4.000 IOPS, measured viaimapsync), if I enable zlib compression in my maildirs, that should lower the number the IOPS (less to read, less to write, less IOPS, more CPU). Dovecot 2.0 is better for zlib (lda support) than dovecot 1.2.X..
- I understand that indexes should go to the fastest storage I own.Somebody talked about storing them in a ramdisk and then backup them to disk on shutdown. I have several questions about that:
For that many users I'm guessing you can't physically stuff enough RAM into the machines in your ESX cluster to use a ramdisk for the index files, and if you could, you probably couldn't, or wouldn't want to, afford the DIMMs required to meet the need.
- In my setup I have 25.000+ users, almost 7.000.000messages in my maildir. How much memory should I need in a ramdisk to hold that?
- What happens if something fails? I think that if Ilose the indexes (ej: kernel crash) the next time I boot the system the ramdisk will be empty, so the indexes should be recreated. Am I right?
Given the size of your mail user base, I'd probably avoid the ramdisk option, and go with a couple of striped (RAID 0) 100+ GB SSDs connected on the iSCSI SAN. This is an ESX cluster of more than one machine correct? You never confirmed this, but it seems a logical assumption based on what you've stated. If it's a single machine you should obviously go with locally attached SATA II SSDs as it's far cheaper with much greater real bandwidth by a factor of 100:1 vs iSCSI connection.
- If I buy a SSD system and export that little and faststorage via iSCSI, does zlib compression applies to indexes?
Timo will have to answer this regarding zlib on indexes.
- Any additional filesystem info? I am using ext3 on RHEL 5.5, inRHEL 5.6 ext4 will be supported. Any performance hint/tuning (I already use noatime, 4k blocksize)?
I'm shocked you're running 25K mailboxen with 7 million messages on maildir atop EXT3! On your fast iSCSI SAN array, I assume with at least 14 spindles in the RAID group LUN where the mail is stored, you should be using XFS.
Formatted with the correct parameters, and mounted with the correct options, XFS will give you _at minimum_ a factor of 2 performance gain over EXT3 with 128 concurrent users. As you add more concurrent users, this ratio will grow even greater in XFS' favor.
XFS was designed specifically, and has been optimized since 1994, for large parallel workloads. EXT3 has traditionally been optimized for use as a single user desktop filesystem. Its performance with highly parallel workloads pales in comparison to XFS:
http://btrfs.boxacle.net/repository/raid/2.6.35-rc5/2.6.35-rc5/2.6.35-rc5_Ma...
If you do add the two ~100 GB SSDs and stripe them via the RAID hardware or via mdadm or LVM, format the resulting striped device with XFS and give it 16 allocation groups. If using kernel 2.6.36 or grater, mount the resulting filesystem with the delaylog option. You will be doing yourself a huge favor, and will be amazed at the index performance.
-- Stan
Thank you for your responses Stan, I reply you belowFor that many users I'm guessing you can't physically stuff enough RAM into the machines in your ESX cluster to use a ramdisk for the index files, and if you could, you probably couldn't, or wouldn't want to, afford the DIMMs required to meet the need.
Yes, I have a cluster of 4 ESX servers. I am going to do some scriptting to see how much space we are allocating to indexes.
- In my setup I have 25.000+ users, almost 7.000.000messages in my maildir. How much memory should I need in a ramdisk to hold that?
- What happens if something fails? I think that if Ilose the indexes (ej: kernel crash) the next time I boot the system the ramdisk will be empty, so the indexes should be recreated. Am I right?
Given the size of your mail user base, I'd probably avoid the ramdisk option, and go with a couple of striped (RAID 0) 100+ GB SSDs connected on the iSCSI SAN. This is an ESX cluster of more than one machine correct? You never confirmed this, but it seems a logical assumption based on what you've stated. If it's a single machine you should obviously go with locally attached SATA II SSDs as it's far cheaper with much greater real bandwidth by a factor of 100:1 vs iSCSI connection.
My SAN(s) (HP LeftHand Networks) do not support SSD, though. But I have several LeftHand nodes, some of them with raid5, others with raid 1+0. Maildirs+indexes are now in raid5, maybe I can separate the indexes to raid 1+0 iscsi target in a different san
- If I buy a SSD system and export that little and faststorage via iSCSI, does zlib compression applies to indexes?
Timo will have to answer this regarding zlib on indexes.
That would be rather interesting.- Any additional filesystem info? I am using ext3 on RHEL 5.5, inRHEL 5.6 ext4 will be supported. Any performance hint/tuning (I already use noatime, 4k blocksize)?
I'm shocked you're running 25K mailboxen with 7 million messages on maildir atop EXT3! On your fast iSCSI SAN array, I assume with at least 14 spindles in the RAID group LUN where the mail is stored, you should be using XFS.
I have two raid5 (7 disks+1 spare) and I have joined them via LVM stripping. Each disk is SAS 15k rpm 450GB, and the SANs have 512 MB-battery-backed-cache. In our real workload (imapsync), each raid5 gives around 1700-1800 IOPS, combined 3.500 IOPS.
Formatted with the correct parameters, and mounted with the correct options, XFS will give you _at minimum_ a factor of 2 performance gain over EXT3 with 128 concurrent users. As you add more concurrent users, this ratio will grow even greater in XFS' favor.
Sadly, Red Hat Enterprise Linux 5 does not support natively XFS. I can install it via CentosPlus, but we need Red Hat support if somethings goes VERY wrong. Red Hat Enterprise Linux 6 supports XFS (and gives me dovecot 2.0), but maybe it is "too early" for a RHEL6 deployment for so many users (sigh).
I will continue investigating about indexes. Any additional hint?
Regards
JavierOn Dec 12, 2010, at 23:26, Javier de Miguel Rodrí guez <javierdemiguel@us.es> wrote:
My SAN(s) (HP LeftHand Networks) do not support SSD, though. But I have several LeftHand nodes, some of them with raid5, others with raid 1+0. Maildirs+indexes are now in raid5, maybe I can separate the indexes to raid 1+0 iscsi target in a different san
I have two raid5 (7 disks+1 spare) and I have joined them via LVM stripping. Each disk is SAS 15k rpm 450GB, and the SANs have 512 MB-battery-backed-cache. In our real workload (imapsync), each raid5 gives around 1700-1800 IOPS, combined 3.500 IOPS.
Your 'slow' storage is running against 16 15k RPM SAS drives? Those LeftHand controllers must be terrible. We have Maildir on NFS on a Netapp with 15k RPM 450GB FC disks and have never had performance problems, even when running the controllers up against the wall by mounting with the noac option (60k NFS IOPS!). We were using 500GB 4500 RPM ATA disks at that point - doesn't get much slower than that.
Our current environment actually houses POP/IMAP/SMTP/web for 60k accounts, and an ESX cluster (12k NFS IOPS) without breaking a sweat. We'll soon be adding 128 1TB disks to the same controllers for Exchange, and should still have capacity to spare.
Not particularly helpful to your situation I know, but next time you are looking at storage you might reevaluate your current strategy.
-Brad
El 13/12/10 10:16, Brad Davidson escribió:
On Dec 12, 2010, at 23:26, Javier de Miguel Rodrí guez<javierdemiguel@us.es> wrote:
My SAN(s) (HP LeftHand Networks) do not support SSD, though. But I have several LeftHand nodes, some of them with raid5, others with raid 1+0. Maildirs+indexes are now in raid5, maybe I can separate the indexes to raid 1+0 iscsi target in a different san I have two raid5 (7 disks+1 spare) and I have joined them via LVM stripping. Each disk is SAS 15k rpm 450GB, and the SANs have 512 MB-battery-backed-cache. In our real workload (imapsync), each raid5 gives around 1700-1800 IOPS, combined 3.500 IOPS.Your 'slow' storage is running against 16 15k RPM SAS drives? Those LeftHand controllers must be terrible. We have Maildir on NFS on a Netapp with 15k RPM 450GB FC disks and have never had performance problems, even when running the controllers up against the wall by mounting with the noac option (60k NFS IOPS!). We were using 500GB 4500 RPM ATA disks at that point - doesn't get much slower than that.
Can you give me (off-list if you desire) more info about your setup? I am interested in the number and type of spindles you are using. We are using LeftHand because of their real time replication capabilities, something very interesting to us, and each node pair is relatively cheap (8x450 GB@15K rpm sas disks per node, real time replication, 512 MB caché, about 25K € each node pair).
We can throw more hardware to this, let's see if using memory-based indexes (via ramdisk) we get better results. Zlib compression on indexes should be great for this.
Regards
JavierOn Mon, 2010-12-13 at 10:26 +0100, Javier de Miguel Rodríguez wrote:
We can throw more hardware to this, let's see if using memory-basedindexes (via ramdisk) we get better results. Zlib compression on indexes should be great for this.
Isn't it possible for Linux to compress the ramdisk? It would be a bit difficult to implement zlib compression for indexes for now. In future they'll be written to via lib-fs API, which would make compression possible too by adding a compression middle layer.
Javier de Miguel Rodríguez put forth on 12/13/2010 3:26 AM:
Can you give me (off-list if you desire) more info about your setup?I am interested in the number and type of spindles you are using. We are using LeftHand because of their real time replication capabilities, something very interesting to us, and each node pair is relatively cheap (8x450 GB@15K rpm sas disks per node, real time replication, 512 MB caché, about 25K € each node pair).
We can throw more hardware to this, let's see if using memory-basedindexes (via ramdisk) we get better results. Zlib compression on indexes should be great for this.
Javier, your number and type of spindles aren't the source of your I/O bottleneck. Your array controller is. Or, more specifically, its lack of enough fast network ports is the problem. The P4300 BK718A model of which you speak only has two 1GbE iSCSI ports. That's only 200 MB/s full duplex. That's less link bandwidth than a single 2 Gbit fiber channel interface. 2 Gbit FC is 2 generations and over 8 years old now. It was superseded by 4 Gbit FC and then 8 Gbit FC, which is the current standard. 8 Gbit FC provides 800 MB/s full duplex bandwidth per link.
Merely two of the 8 SAS drives in the P4300 unit can saturate the iSCSI interfaces on the controller. This has always been the downside of low end iSCSI arrays. The same eight 450GB 15k spindles backed by a decent controller with 512MB to 1GB cache and dual 4 Gbit FC ports or 10 GbE ports would give you well over double the bandwidth using the same RAID level you do now, and would increase IOPS substantially.
You don't need more or faster spindles to increase your performance and decrease interface load Javier. You need more interface throughput than your two 1 GbE ports currently provide. You either need more 1 GbE ports per P4300, say 4 of them, link bonded to your ethernet switch as a single 400 Mb/s full duplex channel (assuming the P4300 supports link bonding), or you need two 10 GbE ports per P4300, if it is upgradeable in this manner. If it is not, you need to move up to another HP model with much greater interface throughput, or a competing vendor's unit with 10 GbE or 8 Gbit FC ports. 1 Gbe iSCSI is a budget solution, not a performance solution, and I think that's what you're beginning to realize.
Nexsan sells a low end 14 drive SAS array with dual 2 GB cache active/active controllers for about the same price you're paying for the P4300, maybe a little less. It has dual 4 Gbit FC ports _and_ dual 1 GbE iSCSI ports. It stomps the P4300 in performance when using the FC ports, offering a sustained 800+ MB/s and around 4,300 IOPS to disk (50K+ to cache), but it doesn't have the advanced management features of the HP unit such as built-in snapshots, etc. IMHO VMware Consolidated Backup is a superior SAN backup solution than node-node replication on the P4000 series, which is just one more load sucking the life out of the two tiny 1 GbE ports. Using VCB with an FC SAN is a much more flexible and higher performance disaster recover solution than vendor specific hardware mirroring of two SAN arrays.
IMHO, you should look into a phased migration to an FC SAN. Qlogic's FC switches and HBAs are excellent, and affordable on a per port and per chassis basis. They are easy to setup. I taught myself to program the switches in the CLI in a day. The web gui may be even easier.
For about $50-60K USD you could have the big brother to the Nexsan unit I mentioned above. It's called the SASBeast. It contains dual active/active controllers, each with 2 GB mirrored cache, 2 8Gbit FC ports, and 2 1GbE iSCSI ports, for a total of 4 8Gb FC ports and 4 1GbE iSCSI ports. It contains 42 x 300, 450, or 600GB SAS 15k drives. It can be expanded with one additional chassis containing another 60 SAS or SATA drives for a total of 104 drives.
It offers sustained throughput of over 1.2 GB/s (about 4 times that of the P4300) and over 12,000+ IOPS to disk with 42 SAS drives, 50K+ to cache, increasing to approximately 30k IOPS to disk with a fully populated expansion chassis w/60 SAS 15K drives, 104 drives total in the array. This device's performance is controller limited, similar to the P4300, but due to the processor, not the interfaces, simply for the fact you can expand it to 104 SAS drives for less than $100K USD. If one needs maximum IOPS and bandwidth rather than total storage, one would be better off buying two SASBeasts than one unit with the expansion chassis. IIRC it's also a little cheaper.
There are many other fine SAN arrays on the market. I mention Nexsan merely because they are very affordable, fast as hell for the price, easy to manage, and I've used them. Due to the low price, they lack the more advanced features of higher priced units, such as snapshots, remote replication, etc. As I mentioned, I'm not a big fan of relying on SAN controllers to perform all my disaster recovery functions, so I do that with software, such as VCB, and a dedicated backup server with a SAN attached robotic library. Thus, the lack of this functionality in the Nexsan units is not an issue here.
-- Stan
Javier, your number and type of spindles aren't the source of your I/O bottleneck. Your array controller is. Or, more specifically, its lack of enough fast network ports is the problem. The P4300 BK718A model of which you speak only has two 1GbE iSCSI ports. That's only 200 MB/s full duplex. That's less link bandwidth than a single 2 Gbit fiber channel interface. 2 Gbit FC is 2 generations and over 8 years old now. It was superseded by 4 Gbit FC and then 8 Gbit FC, which is the current standard. 8 Gbit FC provides 800 MB/s full duplex bandwidth per link.
Hmm... I do not fully agree with your reasoning. An imap server is a lot of random I/O, not too much bandwith. Our LeftHand Networks have two 1 Gbein adaptive load balancing (a kind of active-active connection), meaning 4 gbps full duplex.
I attach you a screenshot of the perfomance of the lefthand: Average: 15 MB/seg, 1.700 IOPS. Highest load (today) is ~62 MB/seg, with a whooping 9000 IOPS, mucho above the theorical iops of 2 raid5 of 8 disks each (SAS 15K), the cache is working as expected, and queue depth of 226 (a bit overloaded, though)
There are many other fine SAN arrays on the market. I mention Nexsan merely because they are very affordable, fast as hell for the price, easy to manage, and I've used them. Due to the low price, they lack the more advanced features of higher priced units, such as snapshots, remote replication, etc. As I mentioned, I'm not a big fan of relying on SAN controllers to perform all my disaster recovery functions, so I do that with software, such as VCB, and a dedicated backup server with a SAN attached robotic library. Thus, the lack of this functionality in the Nexsan units is not an issue here.
We have more than 65k users, and we need active-active disaster recovery. Half of our ESX cluster & lerfthands are in a location, the other half is in other location, and we have tested that shutting down a complete site we can recover in minutes (simply, the VMs start launching in the other one). Only lefthand (in the cheap market) gave us realtime replication of storage, a kind of "network raid 1" for our storage...
I still think that my problem is IOPs related, no bandwith related. My maximum bandwith today was 60 MB/seg, that fits entirely in 1 Gbps, but the queue depth is high because of the lot of iops (9000) that "only" 16 disks can not handle. I can buy better storage heads to delay all that writes, or avoid a lot of them putting the indexes in a SSD or in a ramdisk.
Thank for all the info, I did not know about Nexsan.
Regards
Javier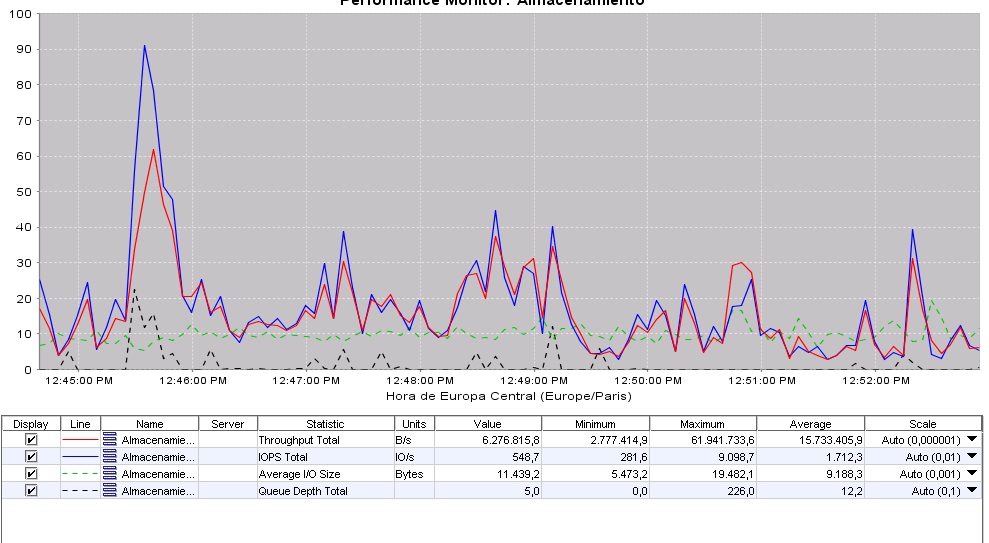{kind=link}
Javier de Miguel Rodríguez put forth on 12/14/2010 6:15 AM:
I attach you a screenshot of the perfomance of the lefthand: Average: 15MB/seg, 1.700 IOPS. Highest load (today) is ~62 MB/seg, with a whooping 9000 IOPS, mucho above the theorical iops of 2 raid5 of 8 disks each (SAS 15K), the cache is working as expected, and queue depth of 226 (a bit overloaded, though)
Ahh, OK. Using RAID5 makes a *lot* of difference with random write IOPS throughput loads such as IMAP with maildir storage or transactional databases. For a transactional load like IMAP I assumed you were using RAID10, which has about double the random write IOPS throughput of RAID5 on most RAID systems.
I still think that my problem is IOPs related, no bandwith related. My
That may very well be the case. As I said, random write IOPS for RAID5 is pretty dismal compared to RAID 10. Your average IOPS is currently 1,700 and your average queue depth is 12. Dovecot is write heavy to index files. A 15K SAS drive maxes at about 250-300 head seeks/sec. With RAID5, due to parity read/modify/write cycles for each stripe block, you end up with about only 2 spindles worth of random write IOPS seek performance, or about 500-600 random write IOPS. This actually gets worse as the number of disks in the parity array increases, although read performance does scale with additional spindles.
With RAID 10, you get full seek bandwidth to half the disks, or about 1000-1200 IOPS for 8 disks. At 1700 average IOPS, you are currently outrunning your RAID5 write IOPS throughput by a factor of 3:1. Your disks can't keep up. This is the reason for your high queue depth. Even if you ran RAID10 on 8 disks they couldn't keep up with your current average IOPS needs. To keep up with your current IOPS load, you'd need
6x15k SAS = 6x300 seeks/sec = 1800 seeks/sec = 12 SAS drives in RAID10
At *minimum* at this moment, you need a 12 drive RAID10 in each P4300 chassis to satisfy your IOPS needs if continuing to store both indexes and mailboxen on the same P4300, which, is impossible as it maxes at 8 drives.
The "load balancing" feature of this product is not designed for parallel transactional workloads.
maximum bandwith today was 60 MB/seg, that fits entirely in 1 Gbps, but the queue depth is high because of the lot of iops (9000) that "only" 16 disks can not handle. I can buy better storage heads to delay all that writes, or avoid a lot of them putting the indexes in a SSD or in a ramdisk.
It's 8 disks, not 16. HP has led you to believe you actually get linear IOPS scaling across both server boxes (RAID controllers), which I'm pretty sure isn't the case. For file server workloads it may scale well, but not for transactional workloads. For these, your performance is limited to each 8 disk box.
What I would suggest at this point, if you have the spare resources, is to setup a dedicated P4300 with 8 disks in RAID10, and put nothing on it but your Dovecot index files (for now anyway). This will allow you to still maximize your mailbox storage capacity using RAID5 on the currently deployed arrays (7 of 8 disks of usable space vs 4 disks with RAID10), while relieving them of the high IOPS generated to/from the indexes.
Optimally, in the future, assuming you can't go with SSDs for the indexes (if you can, do it!), you will want to use the same setup I mention above, with split index and mail store on separate P4300s with RAID10 and RAID5 arrays respectively, but using Linux kernel 2.6.36 or later with XFS and the delaylog mount option for your filesystem solution for box indexes and mail store. Combining all of these things should give you a spindle (not cache) IOPS increase for Dovecot of at least a factor of 4 over what you have now.
Thank for all the info, I did not know about Nexsan.
You're welcome Javier.
Nexsan makes great products, especially for the price. They are very popular with sites that need maximum space, good performance, and who need to avoid single vendor lock-in for replication/backup. Most of their customers have heterogeneous SANs including arrays from the likes of IBM, SUN, SGI, Nexsan, HP, DataDirect, HDS, etc, and necessarily use "third party" backup/replication solutions instead trying to manage each vendor specific hardware solution. Thus, Nexsan forgoes implementing such hardware replication in most of its products, to keep costs down, and to put those R&D dollars into increasing performance, density, manageability, and power efficiency. Their web management GUI is the slickest, most intuitive, easiest to use interface I've yet seen on a SAN array.
They have a lot of high profile U.S. government customers including NASA and many/most of the U.S. nuclear weapons labs. They've won tons of industry awards over the past 10 years. A recent example, Caltech deployed 2 PB of Nexsan storage early this year to store Spitzer space telescope data for NASA, a combination of 65 SATABeast and SATABoy units with 130 redundant controllers:
http://www.nexsan.com/news/052610.php
They have offices worldwide and do sell in Europe. They have a big reseller in the U.K. although I don't recall the name off hand. IIRC, their engineering group that designs the controllers and firmware is in Ireland or England, one of the two.
Anyway, Nexsan probably isn't in the cards for you. It appears you already have a sizable investment in HPs P4xxx series of storage arrays, so it would be logical to get the most from that architecture you can before throwing in another vendor's products that don't fit neatly into your current redundancy/failover architecture.
Although... Did I mention that all of Nexsans arrays support SSDs? :) You can mix and match SSD, SAS, and SATA in tiered storage within all their products.
If not for your multi site replication/fail over requirement, for about $20-25K USD you could have a Nexsan SATABoy with
4 x ~100 GB SSDs in RAID 0 for Dovecot indexes 10 x 1TB SATA II disks in RAID5 for the mail store 2 x 2GB cache controllers w/ 4 x 4Gb FC and 4 x iGb iSCSI
Since you don't have a fiber channel network, you would connect 1 iSCSI port from each controller to your ethernet network and configure multipathing in ESX. You'd export the two LUNs (SSD array and SATA array) and import/mount each appropriately in ESX/Linux. You would connect one ethernet port on one of the controllers to you out of band management network. These are just the basics. Obviously you can figure out the rest.
This setup would give you well over a 1000x fold increase in IOPS to/from the indexes, with about the same performance you have now to the mail store. If you want more mail store performance, go with the SASBoy product with the same SSDs but with 600GB 15k SAS drives. It'll run you about $25-30K USD. But I think the SATABoy in the configuration I mentioned would meet your needs for quite some time to come.
My apologies for the length of these emails. SAN storage is one of my passions. :)
-- Stan
Won't be 15k U320 SCSI disks also faster than average SATA disks for the indexes?
El 15/12/10 14:28, Patrick Westenberg escribió:
Won't be 15k U320 SCSI disks also faster than average SATA disks for the indexes? I am using 2xraid5 of 8 SAS disks of 15k rpm for mailboxes & indexes.
I am evaluating the migration of indexes to 1xraid 1+0 8 disks SAS 15k rpm
Regards
JavierPatrick Westenberg put forth on 12/15/2010 7:28 AM:
Won't be 15k U320 SCSI disks also faster than average SATA disks for the indexes?
Yes. A faster spindle speed allows for greater random IOPS. Index file reads/writes are random IOPS, and become more random with greater concurrency, i.e. more users.
Although, I should point out that parallel SCSI (U320) is pretty much a dead technology at this point. AFAIK, no vendor has shipped a new parallel SCSI disk line (only warranty replacements) for a number of years now. It has been superseded by Serial Attached SCSI (SAS).
I should also point out that the interface itself, whether parallel SCSI, SAS, or SATA, makes little difference for random IOPS performance, as long as the interface is running below the saturation point. The spindle speed and the drive firmware, specifically the queuing implementation, are what make for a good transactional performance disk drive. Typically, 15k drives have the best transactional performance, then 10k, then 7.2k, etc.
-- Stan
Stan Hoeppner schrieb:
Although, I should point out that parallel SCSI (U320) is pretty much a dead technology at this point. AFAIK, no vendor has shipped a new parallel SCSI disk line (only warranty replacements) for a number of years now. It has been superseded by Serial Attached SCSI (SAS).
That's for sure! :)
But if your storage system is selfmade and you have some fast U320 disks left, you could use them for the index files.
Javier de Miguel Rodríguez put forth on 12/13/2010 1:26 AM:
Sadly, Red Hat Enterprise Linux 5 does not support natively XFS. Ican install it via CentosPlus, but we need Red Hat support if somethings goes VERY wrong. Red Hat Enterprise Linux 6 supports XFS (and gives me dovecot 2.0), but maybe it is "too early" for a RHEL6 deployment for so many users (sigh).
I will continue investigating about indexes. Any additional hint?
Dave Chinner is possibly the most prolific/active developer of XFS. He is the author of the XFS delayed logging code (up to 100x+ increase in matadata write throughput). He's a distinguished kernel engineer at Red Hat. I suggest you send an email to
xfs@oss.sgi.com
and ask to be CC'd on replies if you don't join the list.
Briefly, but concisely, describe your current mail storage setup including hardware (SAN topology and storage devices), software, mail box store format, average/peak concurrent user load, and what filesystem you currently use.
Then, save every reply you get and read them at least a couple of times each, thoroughly. You should then realize you're leaving a ton of performance on the table, eating far more resources than you should be, and generating more SAN traffic that what you would using XFS for the same workload, especially if you're able to use delaylog with a recent kernel. Delaylog pushes metadata operation loads almost entirely into memory, dramatically decreasing physical I/Os over the SAN, while simultaneously increasing throughput by an order or magnitude. For large maildir installations such as yours, you're almost committing a crime by using EXT3 and not XFS.
Sadly, until a major distro makes XFS its default enterprise filesystem, the bulk of the Linux world will have no clue what they've been missing for the past 7+ years, which is very sad. For any large parallel workload, XFS trounces EXT3/4/BTRFS/Reiser by a factor of 5-100+ depending on the exact workload.
-- Stan
Quoting Stan Hoeppner <stan@hardwarefreak.com>:
Also, due to the potential size of the index files (mine alone are 276 MB on an 877 MB mbox), you'll need to do some additional research to see if this is a possibility for you.
That's rather high based on my users... My largest user has 110M of indexes. The next highest users are 54M, 52M, 43M, 38M, 32M, 30M, 27M, 23M, 22M, and then tons of users in the teens... So your situation doesn't seem to be the norm...
I guess it depends on your site (users, quotas, number of folders per
user, etc).
-- Eric Rostetter The Department of Physics The University of Texas at Austin
Go Longhorns!
Eric Rostetter put forth on 12/12/2010 9:08 PM:
Quoting Stan Hoeppner <stan@hardwarefreak.com>:
Also, due to the potential size of the index files (mine alone are 276 MB on an 877 MB mbox), you'll need to do some additional research to see if this is a possibility for you.
That's rather high based on my users... My largest user has 110M of indexes. The next highest users are 54M, 52M, 43M, 38M, 32M, 30M, 27M, 23M, 22M, and then tons of users in the teens... So your situation doesn't seem to be the norm...
Oh, I'm positive of that Eirc. :)
I guess it depends on your site (users, quotas, number of folders per user, etc).
About 135 MB of that 276 MB mentioned above is search indexes.
This mailbox has a little over 62,000 emails, stored in mbox format. Most of the 62K reside in less than 10 mbox files (IMAP folders). It's definitely out of the norm. :)
-- Stan
participants (7)
-
Brad Davidson
-
Eric Rostetter
-
Javier de Miguel Rodríguez
-
Javier de Miguel Rodríguez
-
Patrick Westenberg
-
Stan Hoeppner
-
Timo Sirainen